AVL Tree
AVL Tree merupakan salah satu jenis dari BST (Binary Search Tree). Di mana tujuan dari BST (Binary Search Tree) itu sendiri adalah untuk mempersingkat waktu pencarian data. Tapi, bagaimana jika setiap node-node yang dimasukkan ke dalam BST itu hanya menumpuk di bagian sebelah kanan root ataupun bagian sebelah kiri root? Tree menjadi tidak seimbang dan akan memakan banyak waktu ketika kita ingin mencari data dari suatu node yang ada di kanan bawah ataupun kiri bawah. Konsep seperti itu tidak berbeda dengan Konsep Linked List, bukan? Inilah worst-case yang mungkin kita dapat dari BST (Binary Search Tree). Maka dari itu, dibuatlah AVL Tree dengan tujuan untuk menyeimbangkan antara anak dari sebelah kanan root dengan anak yang berada di sebelah kiri root. AVL Tree ini ditemukan oleh G.M. Adelson Veleskii dan E.M. Landis.
AVL Tree sendiri merupakan Binary Search Tree (BST) yang hanya memiliki perbedaan height (tinggi) 1 antara subtree kiri dan subtree kanan. Dengan adanya penyeimbangan ini, pencarian data akan semakin cepat dilakukan. Dalam menyeimbangkan node, dikenal istilah yang bernama Balance Factor sebagai penanda yang jika melebihi aturan AVL Tree akan dilakukan Rotation.
AVL Tree mempunyai aturan yang tidak boleh dilanggar di mana Balance Factor harus mempunyai nilai -1, 0, dan 1. Tidak boleh kurang atau lebih dari nilai tersebut. Jika lebih, harus diseimbangkan kembali dengan melakukan Rotation. Balance Factor dapat ditentukan dengan:
Balance Factor = Height of Left Subtree - Height of Right Subtree
Berikut adalah contoh dari AVL Tree. Kita dapat melihat jika Balance Factor nya tidak melebihi -1, 0, dan 1 yang artinya Tree ini merupakan AVL Tree.

Dari gambar tersebut, Tree memiliki height = 4 dan balance factor yang ada tidak melebihi atau kurang dari -1, 0, dan 1. Height ditentukan dengan berapa jumlah level anak ke bawah yang dimiliki oleh Tree dihitung dari root (level 1). Balance factor ditentukan dari hasil selisih antara height anak kiri dengan height anak kanan. Ambil contoh node (14), mempunyai height 2 dan balance factor 1. Node (14) memiliki 1 anak kiri dengan height 1 dan 1 anak kanan dengan height 2. Hasil pengurangannya adalah 1. Itulah balance factor.
INSERTION : AVL TREE
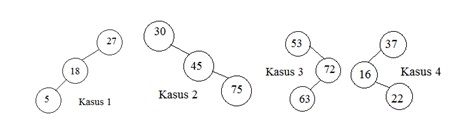
Terdapat 4 kasus penambahan node baru (insert) yang seringkali menyebabkan Tree menjadi tidak seimbang, di antaranya:
1. Left-Left (LL)
Node terdalam terletak pada subtree bagian kiri dari anak kiri T (node yang harus diseimbangkan).
2. Right-Right (RR)
Node terdalam terletak pada subtree bagian kanan dari anak kanan T (node yang harus diseimbangkan).
3. Right-Left (RL)
Node terdalam terletak pada subtree bagian kanan dari anak kiri T (node yang harus diseimbangkan).
4. Left-Right (LR)
Node terdalam terletak pada subtree bagian kiri dari anak kanan T (node yang harus diseimbangkan).
Penyelesaian dari kasus ini adalah dengan melakukan Rotation. Ada 2 cara untuk melakukan Rotation, yaitu:
a. Single Rotation
Single rotation dilakukan bila node dari Tree searah ke arah kiri (Left-Left) atau searah ke arah kanan (Right-Right) yang menyebabkan terjadinya ketidakseimbangan. Kasus 1 dan kasus 2 dapat diselesaikan dengan Single Rotation ini. Pada kasus 1, akan dilakukan right rotate. Pada kasus 2 akan dilakukan left rotate.
Berikut contoh dari Single Rotation.

Pada kasus di atas, penambahan node (12) menyebabkan tree menjadi tidak seimbang. Pada gambar, terjadi kasus 1 (left-left) di mana root (30) memiliki balance factor 2. Hal ini melanggar peraturan dari AVL Tree dengan balance factor yang melebihi 1. Untuk menyelesaikan kasus ini, dilakukan single rotation. Kasus left-left ini dapat diselesaikan dengan melakukan right rotate. Node (22) akan menjadi root, kemudian node (15) akan menjadi anak kiri dari node (22) dan node (30) menjadi anak kanan node (22).
b. Double Rotation
Double rotation dilakukan bila node dari Tree mempunyai anak kanan dan anak tersebut mempunyai anak kiri (Right-Left) atau node dari tree mempunyai anak kiri dan anak tersebut mempunyai anak kanan (Left-Right) sehingga terjadi ketidakseimbangan. Kasus 3 dan kasus 4 dapat diselesaikan dengan Double Rotation. Di mana ada 2x rotasi yang dilakukan.
Pada kasus 3, langkah pertama adalah dengan melakukan right rotate kemudian dilanjutkan dengan left rotate. Pada kasus 4, langkah pertama adalah dengan melakukan left rotate kemudian diikuti dengan right rotate.
Berikut contoh dari Double Rotation.
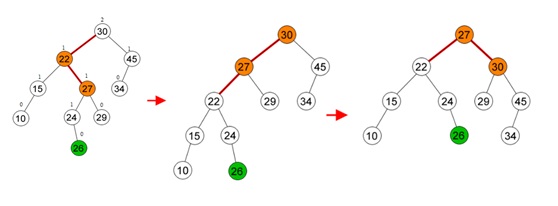
Pada kasus di atas, terjadi ketidakseimbangan pada tree. Kasus yang terjadi adalah left-right. Diperlukan double rotation untuk menyeimbangkannya. Langkah pertama adalah dengan melakukan left rotate pada node (22) dan node (27) menjadi seperti pada gambar di atas. Setelah itu, dilakukan 1x rotasi lagi karena masih belum seimbang. Dilakukan right rotate dengan menjadikan node (27) menjadi root, node (22) menjadi anak kiri dari node (27), dan node (30) menjadi anak kanan dari node (27).
DELETION : AVL TREE
Terdapat 2 kasus yang biasanya terjadi ketika melakukan penghapusan (delete) node, di antaranya:
1. Jika node yang berada di posisi paling bawah (leaf), node akan dapat langsung dihapus.
2. Jika node yang akan dihapus memiliki anak, harus dicek kembali apakah setelah penghapusan node tree akan menjadi tidak seimbang atau tidak. Pengecekan penyeimbangan node ini sama seperti pada saat Insertion. Jika tree menjadi tidak seimbang, maka harus diseimbangkan lagi.
Berikut contoh dari Deletion.
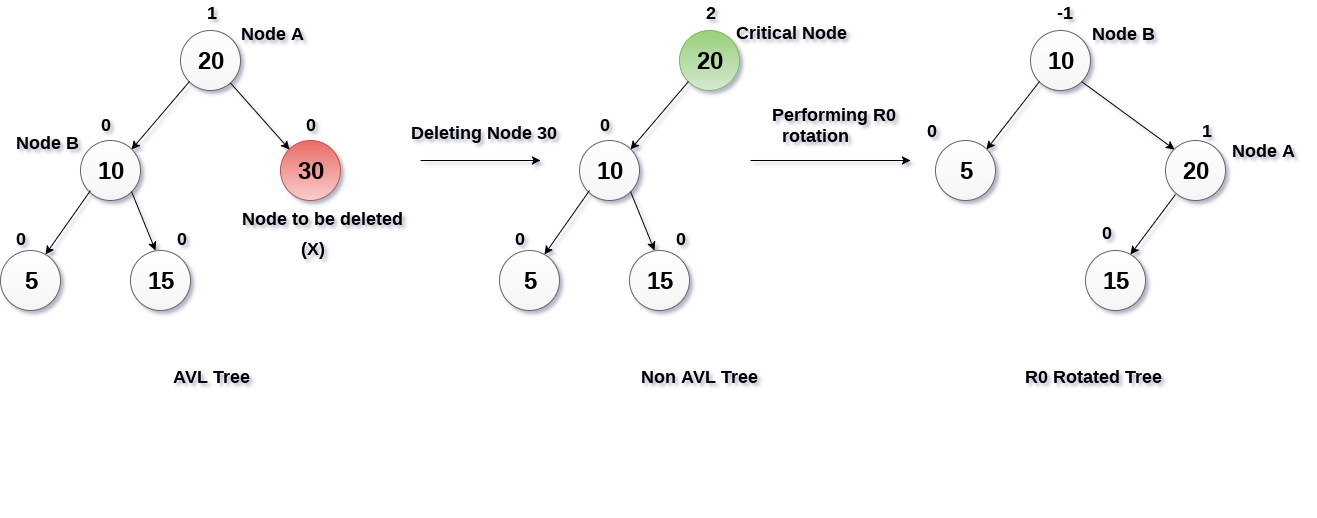
Pada gambar di atas, node (30) akan dihapus. Node (30) ini merupakan leaf dari tree sehingga pengoperasian deletion dapat langsung dilakukan. Namun setelah operasi deletion dilakukan, terjadi ketidakseimbangan pada tree. Node (20) memiliki balance factor 2 di mana hal ini melanggar aturan dari AVL Tree itu sendiri. Tree harus diseimbangkan. Pada kasus di atas, terjadi kasus left-left di mana kita harus melakukan rotation untuk menyeimbangkannya kembali. Kita lakukan right rotate dengan menjadikan node (10) menjadi root dengan anak kanan node (20) dan anak kiri node (5). Ternyata balance factor dari node (10) sudah memenuhi syarat AVL Tree yaitu -1. Maka, tree sudah seimbang.